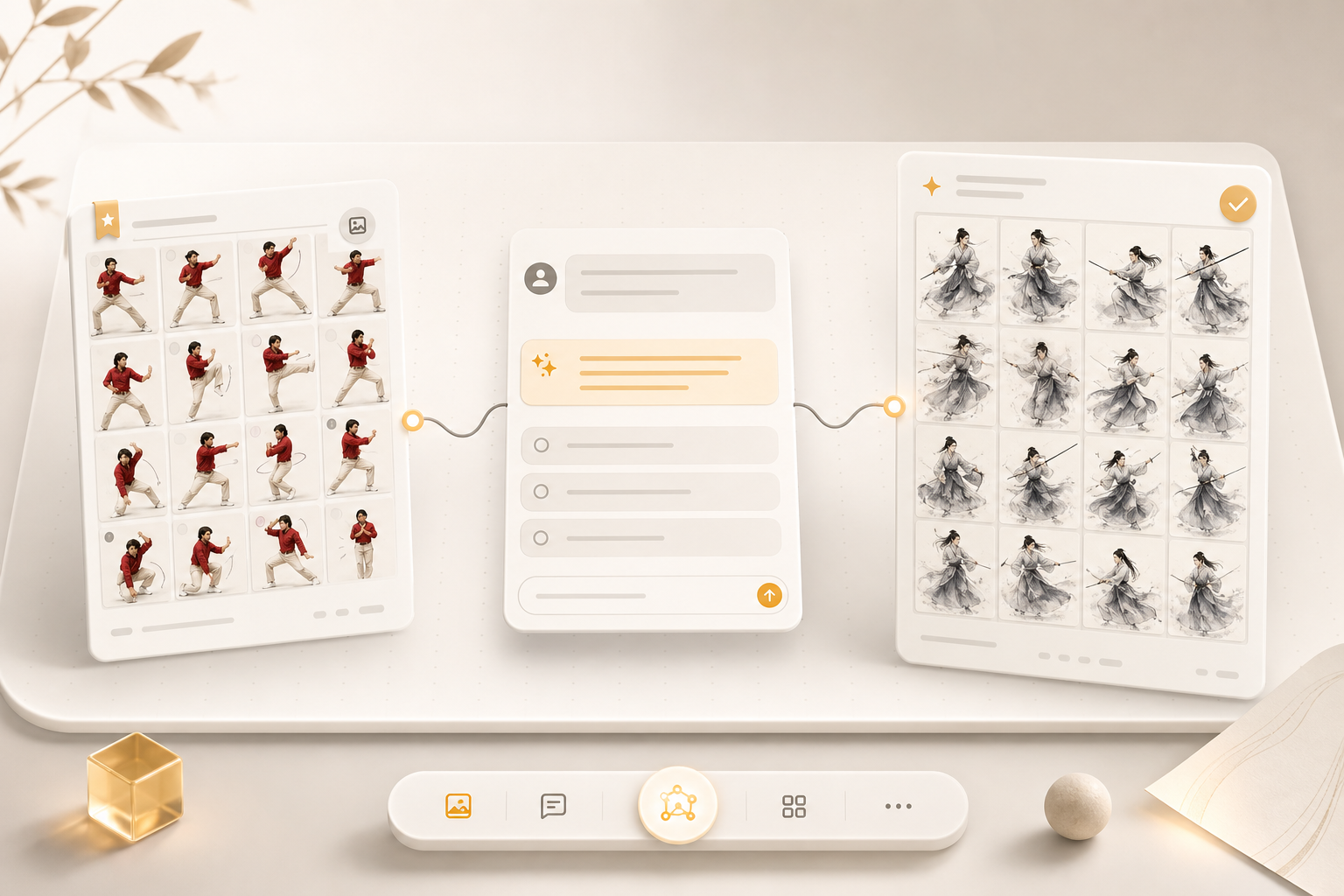
AI 生图最难的地方,常常不是模型不够强,而是创作者很难一次性把需求说完整。
一张参考图里有构图、色彩、主体、版式、字体、镜头、材质和情绪;一个真实项目里还会有品牌、产品、角色、分镜、用途和交付比例。把这些信息压成一句提示词,往往会丢掉很多关键意图。
献丑 AI 画布里的「对话生图」就是为了解决这个问题:它不要求你一上来写出完美提示词,而是让参考图、画布素材和 AI 对话一起工作。你可以先放入参考图,再把角色图、产品图、场景图等素材连到它,接着通过多轮问答把需求逐步说清楚。最后,AI 会输出可直接用于生成的提示词,并在画布中创建文生图或图生图节点。
从参考图开始,而不是从空白输入框开始
对话生图的入口是一类新的画布节点:参考图节点。它可以来自参考图库,也可以从已有图片节点继续派生。
参考图库按故事板、角色图、场景图和其他类型组织素材。用户选择一张参考图后,画布会保留它的图片、标题、分类、比例、来源链接以及可能存在的原始提示词。这个节点不是普通图片预览,而是一个带上下文的创作模板。
如果你从已经生成的图片继续发起对话生图,系统会尽量带上这张图的来源提示词和比例。这样,上一轮生成结果可以继续作为下一轮创作的母版,而不是变成孤立图片。
这带来一个很重要的变化:创作不再是「写一句话,抽一张图」,而是「把一张图变成可追问的方案」。参考图提供视觉目标,画布连线提供素材关系,AI 对话负责把模糊需求拆成可执行提示词。
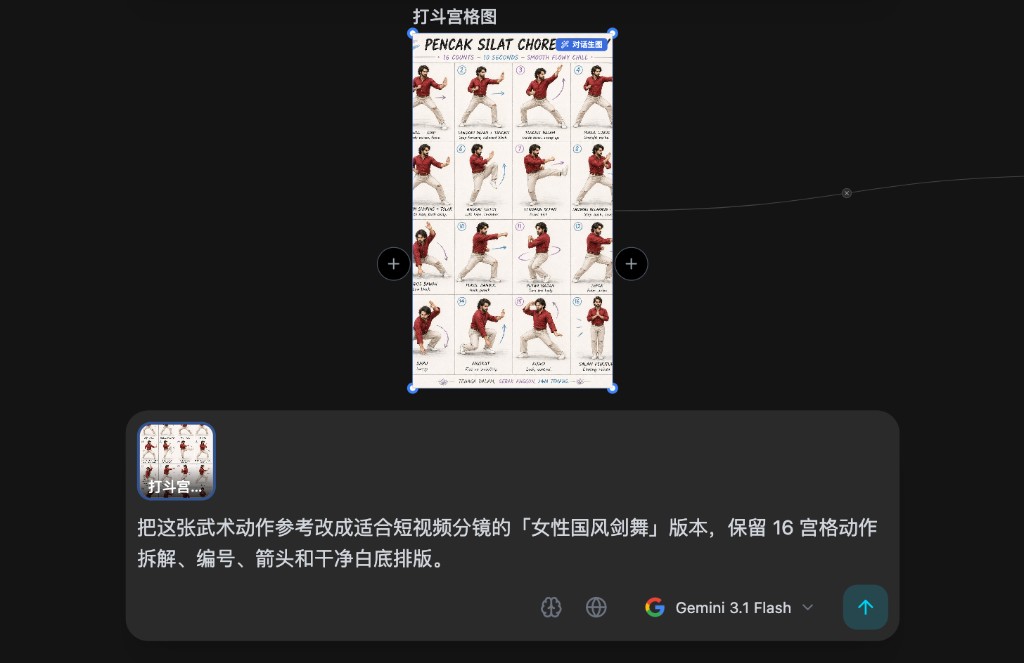
对话生图的工作方式
打开对话生图后,系统会进入一个全屏对话窗口。它会把参考图作为视觉附件发送给 AI,同时把画布上连入的图片、视频或主体节点作为素材引用传入上下文。
用户看到的是一个很简单的流程:补充一句需求,选择视觉模型,必要时打开深度思考或联网搜索,然后开始对话。但在背后,系统已经做了几件关键事情。
第一,参考图和素材会被转成模型可访问的绝对链接。这样远程视觉模型不只是读文字,而是真的能看到参考图和连入素材。
第二,系统会把首轮任务指令固定在对话历史前面。即使后面进行了多轮追问,AI 也不会轻易忘记参考图、母版提示词和素材清单。
第三,对话不会污染右侧普通 AI 对话历史。对话生图是临时会话,关闭后即销毁,适合围绕某一张参考图快速决策。
第四,AI 的输出被设计成可识别结构。它不是随便写一段建议,而是要用结构化问卷收集信息,或者用专门的最终提示词格式交付结果。前端识别到最终提示词后,会展示「最终提示词预览」和「在画布中创建」按钮。
有提示词母版时:保留结构,只改该改的地方
很多优秀参考图并不只是一张图,它背后还有一套精心设计的提示词结构。例如分镜图会有镜号、景别、动作、字幕和版式;角色图会有三视图、服装、表情、材质和设定页排版;场景图会有空间层次、光照、地标、天气和镜头视角。
对话生图在有参考提示词时,会把它当作母版,而不是普通参考。
这意味着 AI 会先解析原提示词的段落顺序、小标题、镜号编号、术语、画风、色调、排版、字体和稳定描写。后续生成最终提示词时,它会尽量沿用这些结构,只替换用户明确要改动的字段,例如品牌名、剧情、角色身份、产品、标语或主体素材。
这种方式特别适合做系列化内容。比如你找到一张成熟的故事板模板,只想把剧情换成自己的短片;或者你喜欢某张角色设定页的版式,只想换成自己的角色。对话生图不会把原模板重写成另一套风格,而是帮你在稳定结构内做最小改动。
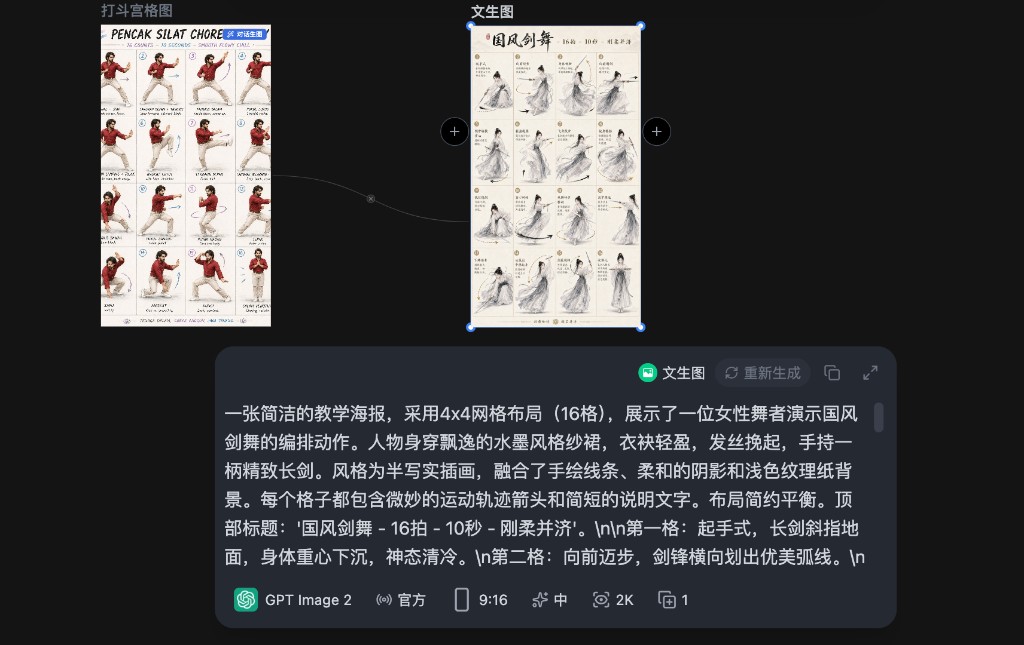
没有提示词时:先选择文生图还是图生图
并不是每张好图都有现成提示词。很多参考图只有视觉内容,没有文字母版。
在这种情况下,对话生图不会假装知道原提示词。它会先观察参考图的视觉内容,归纳图片类型、主体、构图、版式、镜头、色彩、材质、文字、标识、比例和可复用规律,然后第一轮就询问用户要走哪种生成方式。
如果选择文生图,AI 会把参考图的视觉方向转写成完整提示词,最终在画布里创建文生图节点。这个方案适合你想借鉴风格、构图或氛围,但不想把原图本身作为生成输入。
如果选择图生图,系统会默认把当前参考图作为源图,AI 会进一步确认哪些元素要保留、哪些内容要替换、风格变化强度多大、是否沿用原图版式。这个方案适合保留参考图结构,做局部改造、主题替换或风格迁移。
这一步看似简单,但非常关键。很多生图失败不是因为提示词差,而是生成方式一开始就选错了。对话生图把「文生图还是图生图」变成一个可讨论的方案决策,而不是隐藏在参数面板里的技术选项。
结构化问卷让需求收敛更快
普通聊天式创作经常会遇到一个问题:AI 问了一大串开放问题,用户不知道先回答哪个,也不知道回答到什么程度才够。
对话生图采用结构化问卷。AI 每轮最多提少量关键问题,并给出 2 到 4 个短选项。用户可以直接点击选项,也可以输入自定义答案。前端会把答案整理成结构化回复,再发送给 AI 继续推理。
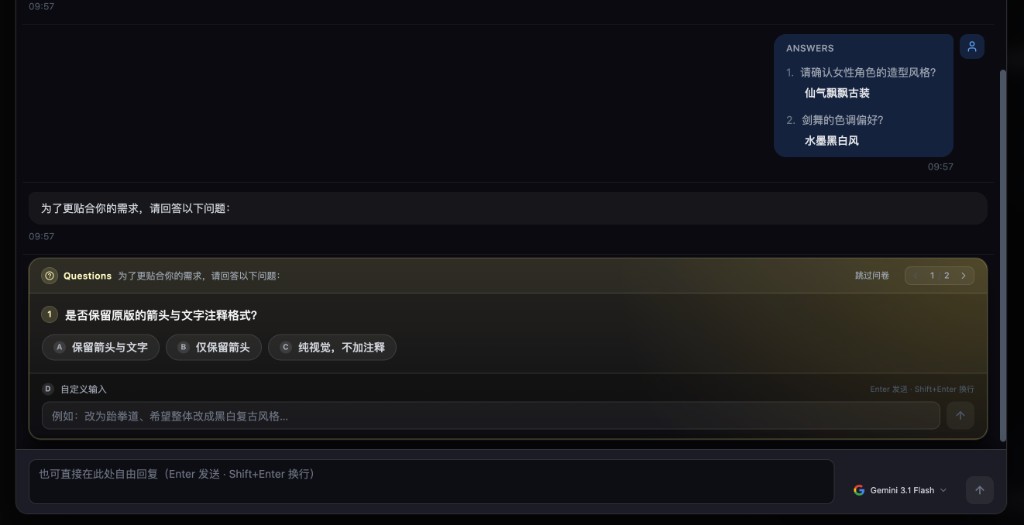
这种交互的优势很明显。
它降低了表达门槛。新手不需要懂「景别」「材质」「构图」等术语,也能通过选项做决策。
它减少了跑偏。AI 每轮只问最关键的字段,避免把创作者带进无关细节。
它适合快速迭代。用户可以跳过问卷,让 AI 基于已有信息直接给出最终提示词;也可以继续对话调整,直到方案符合预期。
它让结果更容易被系统识别。最终提示词不是普通段落,而是会被前端提取并展示为预览卡片,确认后直接创建节点。
方案对比:先比较创意路线,再进入生成
对话生图解决的是「围绕一张参考图收敛最终提示词」。而在更开放的 AI 对话中,献丑还支持另一种很实用的能力:提示词方案卡片。
当 AI 回复中包含多套图片或视频提示词方案时,系统会自动识别这些方案,并把它们渲染为独立卡片。每张卡片都有方案名、完整提示词和创建入口。图片方案会根据是否存在图片来源,创建文生图或图生图;视频方案会根据图片来源数量,创建文生视频、首帧生视频、首尾帧生视频或参考生视频。
这对创作团队特别有价值。因为真实项目一开始往往不是缺一个提示词,而是缺少比较。
同一个广告主题可以有高端极简、赛博霓虹、手绘插画和电影写实几种方向;同一个角色可以有国风、机甲、校园、暗黑奇幻几种版本;同一个短视频镜头可以走产品展示、剧情反转、氛围铺垫或强视觉冲击。
如果每个方向都要复制提示词、手动新建节点、重新配置参数,创作者很快会被操作成本打断。方案卡片把「比较」提前到对话阶段,把「执行」压缩成一次点击。你可以先看清不同路线的差异,再选择最值得生成的那一个。

和传统生图流程相比,优势在哪里
对话生图不是替代文生图或图生图,而是把它们前面的决策过程补齐。
和直接文生图相比,对话生图更适合复杂需求。它能读参考图、读画布素材、追问关键字段,并在信息足够后再生成提示词,减少一次性输入带来的遗漏。
和普通图生图相比,对话生图更强调「为什么这样改」。它会先确认保留和替换关系,而不是把原图和一句描述直接丢给模型。
和单纯参考图库相比,对话生图让参考图变成可复用模板。参考图库不只是找灵感,而是能把分镜、角色、场景、海报等成熟结构迁移到新项目。
和普通聊天机器人相比,它更贴近画布工作流。AI 的答案不是停留在文本里,而是能被解析成问卷、最终提示词、方案卡片和新节点。用户确认后,结果会继续留在画布中,进入后续生成、对比、编辑和视频创作流程。
更适合哪些创作场景
对话生图尤其适合参考明确、但目标还没完全说清楚的项目。
做故事板时,你可以选一张成熟分镜模板,让 AI 先保留镜号、版式和镜头结构,再逐步替换剧情和角色。
做角色设定时,你可以用参考角色图保留三视图、立绘或设定页结构,再把服装、年龄、气质、武器和素材引用换成自己的角色。
做场景概念时,你可以保留参考图的空间层次、光照和镜头视角,再替换地点、天气、时代背景或关键道具。
做品牌、电商和海报时,你可以保留排版、材质、色彩和视觉节奏,再替换产品、标语、品牌名和促销信息。
做创意探索时,你可以先让 AI 输出多套提示词方案,通过方案卡片比较不同方向,再把最有潜力的方案创建到画布里继续生成。
画布工作流的真正价值
AI 生图正在从「拼提示词」进入「搭流程」阶段。
一张好图不是孤立结果,它往往来自参考图、素材、参数、模型、提示词、历史版本和团队判断的共同作用。对话生图把这些信息连接起来,让创作者不必在聊天窗口、素材文件夹、参数面板和生成结果之间来回搬运。
你可以把参考图放在画布上,把素材连过去,用对话把需求问清楚,再用确认按钮创建新节点。之后,这个节点还可以继续生成图片、进入视频、变成新参考,或者作为团队讨论的中间稿。
这就是献丑 AI 画布想解决的问题:不是让 AI 替你做所有选择,而是让每一次选择都更清楚、更可控、更容易落地。
对话生图和方案对比的组合,让创作流程从「一次性猜答案」变成「边看、边问、边比较、边生成」。对于需要稳定产出图片、分镜、角色、场景和视频素材的创作者来说,这比单次生成更接近真正的生产力。


